
📊 Benchmarking
We believe it's important to be transparent and continuously evaluate our APIs and compare them vs. direct usage of LLMs for healthcare AI tasks. As such we conduct ongoing benchmarking and open-source the results and benchmarking code. Benchmarking repo: https://github.com/PhenoML/phenoml_benchmarks
Below are some results of the latest benchmarking of lang2FHIR API compared to direct usage of LLMs to generate a variety of FHIR Resources.
In the latest analysis, we see that while all APIs generate valid FHIR as evaluated by the public FHIR Validator, PhenoML lang2FHIR API outperforms direct usage of major commercial AI APIs on code matching (100% success rate on the 32 test cases compared to approximately 30-60% success rate for commercial APIs) and outperforms Anthropic and OpenAI (o4-mini) on latency.
While direct usage of LLM APIs can generate accurate codes for some test cases, for less common codes, code hallucination is probable. Lang2FHIR currently utilizes Gemini as an LLM and we are now extending it to support Private LLM usage to enable completely private FHIR generation.
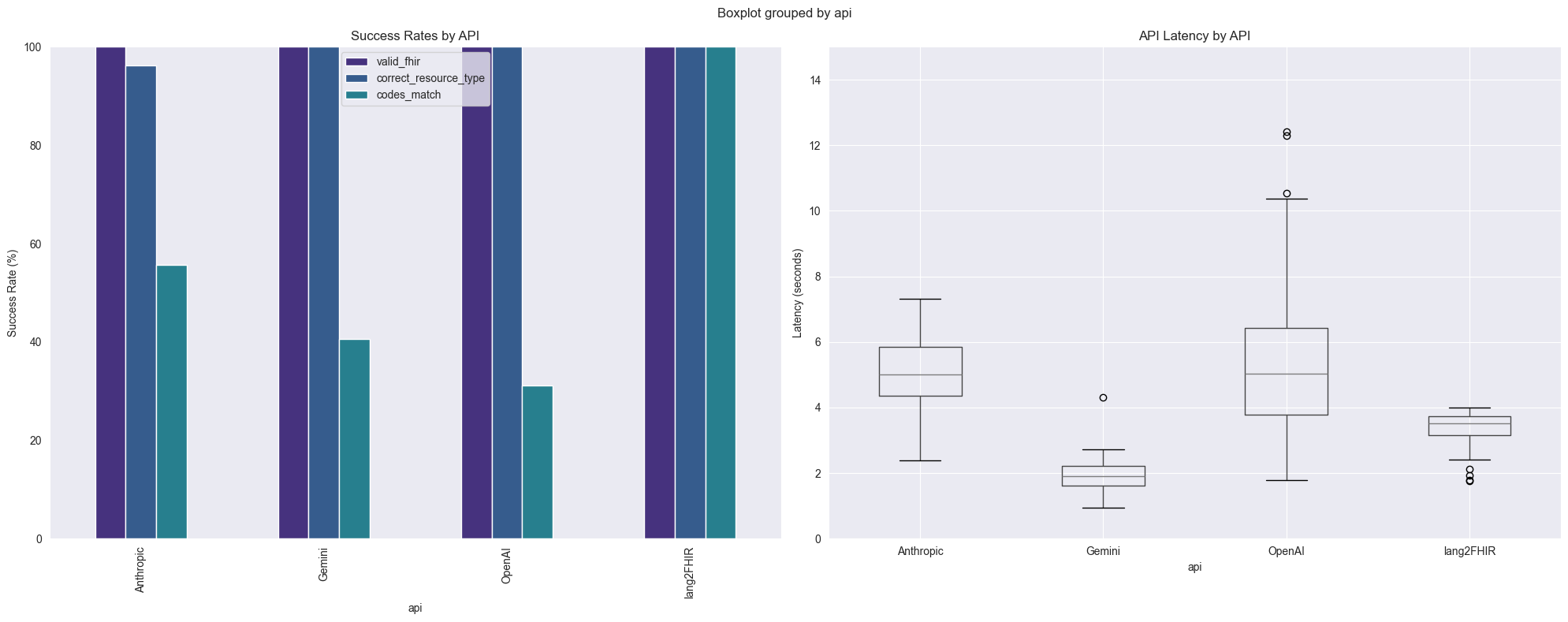
Generated results as of: 2025-03-11
Updated 11 months ago